Introduction
Picture this: It’s 2 AM on a Tuesday, and your phone buzzes with an alert that makes your heart skip a beat. Your company’s security monitoring system has detected unusual network activity that screams “breach.” What happens next could determine whether this becomes a minor hiccup or a catastrophic event that makes headlines for all the wrong reasons.
Handling security incidents effectively isn’t just about having the right tools—it’s about having a systematic approach that turns chaos into controlled response. Whether you’re a seasoned IT professional or someone thrust into the cybersecurity spotlight, understanding the incident response process can be the difference between containing a threat quickly and watching it spiral into a business-ending disaster.
In this guide, we’ll walk through the essential steps of security incident management, explore real-world scenarios, and provide you with actionable strategies that actually work when the pressure is on. Because when cyber threats strike, there’s no time for guesswork.
What Exactly Constitutes a Security Incident?
Before diving into response procedures, let’s clarify what we’re dealing with. A cybersecurity incident isn’t just any technical glitch—it’s any event that compromises the confidentiality, integrity, or availability of your organization’s information systems.
Common types include:
- Ransomware attacks that encrypt critical business data
- Phishing campaigns targeting employee credentials
- Data breaches exposing customer information
- Malware infections spreading across network systems
- Insider threats from disgruntled or compromised employees
- DDoS attacks overwhelming your online services
The key is recognizing these incidents early. According to recent industry data, organizations that identify breaches within 200 days save an average of $1.12 million compared to those that take longer.
The 6-Phase Incident Response Lifecycle
Phase 1: Preparation – Building Your Defense Foundation
Think of preparation as your insurance policy. You hope you’ll never need it, but when disaster strikes, you’ll be grateful it exists.
Essential preparation steps include:
- Establishing an Incident Response Team (IRT) with clearly defined roles
- Creating detailed incident response playbooks for different scenarios
- Implementing monitoring tools and SIEM platforms for early detection
- Conducting regular training exercises and tabletop simulations
- Maintaining updated contact lists for internal teams and external partners
A well-prepared organization can contain incidents 77% faster than those caught off-guard. Your future self will thank you for the groundwork laid today.
Phase 2: Detection and Analysis – The Critical First Hours
This is where your monitoring investments pay dividends. Incident detection relies heavily on automated systems, but human expertise remains irreplaceable for analysis.
Key detection sources:
- Security Information and Event Management (SIEM tools)
- Endpoint detection and response platforms
- Network monitoring systems
- User behavior analytics
- Employee reports of suspicious activities
During analysis, focus on these critical questions:
- What type of incident are we dealing with?
- How extensive is the compromise?
- What systems and data are affected?
- Is this an ongoing attack or a completed breach?
Incident severity classification becomes crucial here. Not every alert deserves a full-scale response, but missing a critical incident can be catastrophic.
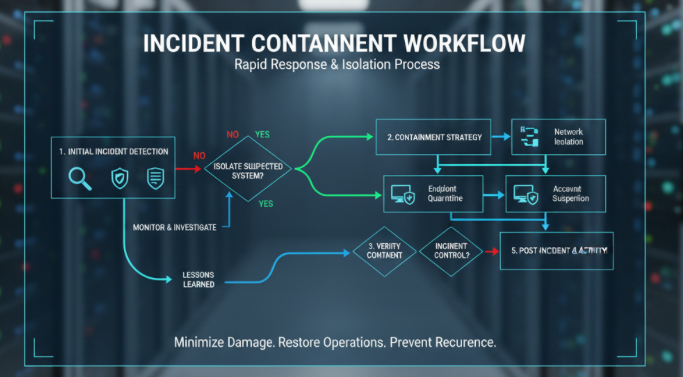
Phase 3: Containment – Stopping the Bleeding
Incident containment comes in two flavors: short-term and long-term. Think of short-term containment as applying a tourniquet—it stops immediate damage but isn’t a permanent solution.
Short-term containment strategies:
- Isolating affected systems from the network
- Disabling compromised user accounts
- Blocking malicious IP addresses
- Taking critical systems offline if necessary
Long-term containment focuses on maintaining business operations while keeping threats at bay:
- Implementing additional monitoring on suspected systems
- Applying security patches and updates
- Strengthening access controls
- Creating secure backup communication channels
Phase 4: Investigation and Evidence Gathering
This phase requires the detective skills of Sherlock Holmes combined with the technical precision of a surgeon. Digital forensics and thorough investigation help you understand not just what happened, but how to prevent it from happening again.
Investigation best practices:
- Preserve evidence using forensically sound methods
- Document everything with timestamps and screenshots
- Interview relevant personnel about suspicious activities
- Analyze log files and network traffic patterns
- Coordinate with legal teams for potential law enforcement involvement
Remember: evidence preservation isn’t just about catching the bad guys—it’s about learning from the incident and strengthening your defenses.
Phase 5: Eradication and Recovery
Now comes the cleanup crew. Eradication means removing the threat completely, while recovery focuses on restoring normal operations.
Eradication steps:
- Remove malware and close security vulnerabilities
- Rebuild compromised systems from clean backups
- Reset passwords for affected accounts
- Update security configurations and rules
- Patch systems that enabled the initial compromise
Recovery considerations:
- Gradual restoration of services with enhanced monitoring
- Verification that systems are truly clean before reconnection
- Communication with stakeholders about service restoration
- Enhanced security measures during the recovery period
Communication During Crisis: Who, When, and How
Incident communication can make or break your response efforts. Poor communication creates confusion, while clear updates maintain confidence and coordination.
Internal Communication Framework
| Timeframe | Audience | Message Type | Key Information |
|---|---|---|---|
| 0-1 hours | Incident Response Team | Alert Notification | Basic incident details, severity level |
| 1-4 hours | Management/Executives | Status Update | Impact assessment, initial containment actions |
| 4-8 hours | IT Staff/Department Heads | Operational Update | Affected systems, workarounds, timeline |
| Daily | All Stakeholders | Progress Report | Investigation status, recovery milestones |
External Communication Considerations
When to notify external parties:
- Regulatory requirements mandate disclosure
- Customer data has been compromised
- Business partners are potentially affected
- Law enforcement assistance is needed
- Public safety concerns arise
The golden rule: be honest, timely, and transparent while avoiding speculation about ongoing investigations.
Phase 6: Post-Incident Activities – Learning and Improving
The incident may be over, but your work isn’t finished. Post-incident review transforms painful experiences into valuable lessons.
Essential post-incident activities:
- Conduct thorough lessons learned sessions
- Update incident response plans based on findings
- Implement additional security measures
- Provide additional training where gaps were identified
- Create detailed incident reports for compliance purposes
Organizations that consistently perform post-incident reviews reduce their average incident response time by 35% and decrease repeat incidents by 60%.
Essential Tools for Modern Incident Response
The right tools can transform your incident response capabilities from reactive scrambling to proactive defense. Here are categories worth considering:
SIEM and Detection Platforms:
- Splunk Enterprise Security – Comprehensive visibility and investigation capabilities
- Microsoft Sentinel – Cloud-native SIEM with AI-driven threat detection
- IBM QRadar – AI-powered security intelligence platform
SOAR and Automation Tools:
- Palo Alto Networks Cortex XSOAR – Automated incident response workflows
- LogRhythm NextGen SIEM – Integrated SIEM, UEBA, and SOAR capabilities
Endpoint Protection and Response:
- CrowdStrike Falcon – Advanced endpoint protection with integrated response
- Rapid7 InsightIDR – Comprehensive detection and incident response solution
The key isn’t having every tool available—it’s selecting the right combination that fits your organization’s size, complexity, and risk profile.
Building Your Incident Response Dream Team
Technology alone doesn’t handle incidents—people do. Your Incident Response Team needs diverse skills and clear responsibilities:
Essential roles:
- Incident Commander – Overall response coordination
- Security Analyst – Technical investigation and analysis
- Communications Lead – Internal and external messaging
- Legal Representative – Compliance and regulatory guidance
- IT Operations – System restoration and technical implementation
Skills and training requirements:
- Regular scenario-based exercises
- Cross-training to prevent single points of failure
- Stress management and decision-making under pressure
- Technical certifications in relevant security domains
Common Pitfalls and How to Avoid Them
Even well-intentioned organizations make mistakes during incident response. Here are the most common traps:
The Panic Trap: Rushing to “fix” everything without proper analysis often makes situations worse. Take time to understand before taking action.
The Communication Vacuum: Silence creates anxiety and speculation. Regular updates, even if there’s nothing new to report, maintain confidence.
The Evidence Destruction: Hastily “cleaning” systems can destroy valuable forensic evidence. Always preserve before you purge.
The Blame Game: Focusing on who caused the incident instead of how to fix it wastes precious time and damages team morale.
Measuring Incident Response Success
How do you know if your incident response metrics indicate success? Track these key performance indicators:
- Mean Time to Detection (MTTD) – How quickly you identify incidents
- Mean Time to Containment (MTTC) – Speed of initial response
- Mean Time to Recovery (MTTR) – Full service restoration duration
- Incident Recurrence Rate – Effectiveness of remediation efforts
- False Positive Rate – Efficiency of detection systems
Industry benchmarks suggest excellent organizations achieve MTTD under 24 hours, MTTC under 4 hours, and MTTR under 72 hours for major incidents.
Preparing for Future Threats
Incident response plan testing isn’t a one-and-done activity. Threats evolve, technologies change, and organizations grow. Regular testing and updates ensure your plans remain effective.
Testing methodologies:
- Tabletop exercises for decision-making practice
- Red team simulations for realistic attack scenarios
- Technical drills for specific response procedures
- Cross-functional workshops for communication practice
Schedule these activities quarterly for high-risk environments, semi-annually for most organizations.
Conclusion
Handling security incidents effectively requires preparation, practice, and perseverance. The organizations that weather cyber storms best aren’t necessarily those with the biggest budgets—they’re the ones with clear processes, trained teams, and the wisdom to learn from each experience.
Remember: every incident, whether major or minor, is an opportunity to strengthen your security posture. The goal isn’t to never have incidents (that’s impossible in today’s threat landscape), but to handle them so well that they become stepping stones to greater resilience.
Start building your incident response capabilities today. Your future self—and your organization—will thank you when the next inevitable cyber challenge arrives.
What’s your biggest concern about incident response in your organization? Share your thoughts in the comments below, and let’s help each other build stronger cyber defenses.
Frequently Asked Questions
What are the essential steps in handling security incidents?
The six essential phases are: Preparation, Detection and Analysis, Containment, Investigation and Evidence Gathering, Eradication and Recovery, and Post-Incident Activities. Each phase builds on the previous one to ensure comprehensive incident management from initial detection through lessons learned.
How do I identify if a security incident has occurred?
Security incidents are typically identified through automated monitoring systems (SIEM platforms, endpoint detection tools), unusual system behavior, employee reports, or external notifications. Key indicators include unexpected network traffic, system performance issues, unauthorized access attempts, or alerts from security tools.
What is the role of an Incident Response Team (IRT)?
An Incident Response Team coordinates all aspects of incident management, from initial detection through final resolution. The team typically includes an Incident Commander, Security Analysts, Communications Lead, Legal Representative, and IT Operations personnel, each with specific responsibilities for effective incident handling.
How is incident severity assessed and categorized?
Incident severity is typically assessed based on factors like potential impact on business operations, types of data involved, number of affected systems, and regulatory implications. Most organizations use a tiered system (Critical, High, Medium, Low) with specific criteria and escalation procedures for each level.
What are the best practices for containing a security incident?
Best practices include immediate isolation of affected systems, preserving evidence for investigation, implementing short-term containment measures to stop ongoing damage, followed by long-term containment strategies that maintain business operations while preventing incident spread. Always document all actions taken.
When should external parties be notified about an incident?
External notification is required when regulatory compliance mandates disclosure, customer data has been compromised, business partners are potentially affected, law enforcement assistance is needed, or public safety concerns arise. Timing and content of notifications should follow legal guidance and regulatory requirements.
Sources: