Three weeks ago, I watched a mid-sized law firm scramble to respond to a potential data breach. The problem wasn’t that their systems were compromised—it was that they had no idea what data was actually at risk. Client files, internal memos, and public marketing materials were all stored with the same security level, making it impossible to assess the true impact.
This scenario highlights why information classification for better security isn’t just a compliance checkbox—it’s the foundation of effective data protection. When you can’t distinguish between your crown jewels and your grocery lists, you can’t protect what matters most.
In this guide, you’ll learn how to implement robust classification policies, understand different data classification levels, and discover the tools that can automate this critical security process. Whether you’re protecting client data, intellectual property, or personal information, proper classification transforms chaotic data into organized, secure assets.
What Is Information Classification and Why It Matters
Information classification is the systematic process of categorizing data based on its sensitivity, value, and potential impact if compromised. Think of it like organizing your house—you wouldn’t store jewelry and old newspapers in the same unlocked drawer.
The law firm I mentioned? They implemented a comprehensive classification system and discovered that 73% of their “sensitive” folders actually contained public information, while truly confidential client data was scattered across unsecured shared drives. This revelation allowed them to focus their security budget where it actually mattered.
The Hidden Costs of Poor Classification
Organizations without proper data protection strategies face significant risks:
- Average data breach cost: $4.45 million globally
- Compliance violations: Up to 4% of annual revenue in GDPR fines
- Recovery time: 287 days average to identify and contain breaches
- Reputation damage: Often irreversible for small businesses
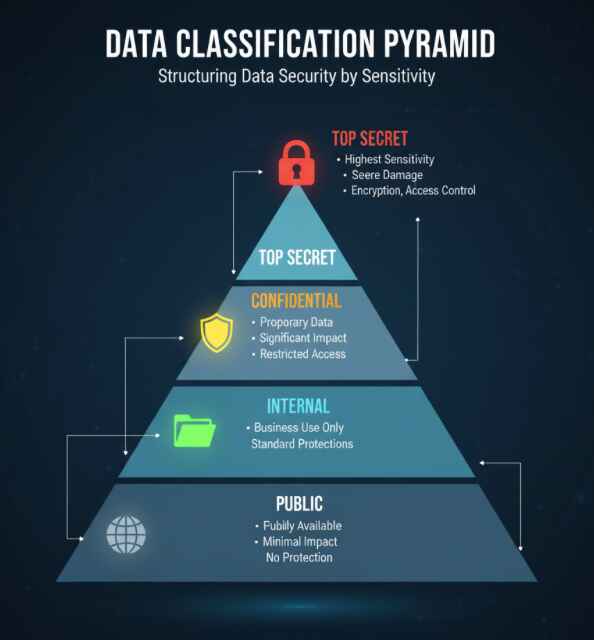
Understanding Data Classification Levels
Data classification levels typically follow a four-tier structure that determines how information should be handled, stored, and shared.
| Classification Level | Definition | Examples | Access Requirements |
|---|---|---|---|
| Public | Information freely available | Marketing materials, press releases | No restrictions |
| Internal | Information for internal use | Employee directories, policies | Company authentication |
| Confidential | Sensitive business information | Financial reports, contracts | Role-based access control |
| Restricted | Highly sensitive data | Personal data, trade secrets | Multi-factor authentication + approval |
Real-World Classification Scenarios
I once helped a healthcare organization classify patient records. Initially, they treated all medical data as “restricted,” which created unnecessary bottlenecks for routine administrative tasks. After proper classification, appointment schedules became “internal,” while diagnostic results remained “restricted”—improving workflow without compromising security.
Benefits of Implementing Classification Policies
Classification policies create a structured approach to data protection that delivers measurable benefits across your organization.
Enhanced Security Posture
When you know exactly what data you’re protecting, you can implement appropriate security controls. Sensitive data classification enables you to apply encryption to confidential files while leaving public documents unencrypted, optimizing both security and performance.
Streamlined Compliance Management
Regulatory compliance classification makes audits significantly easier. Instead of treating all data as potentially sensitive, you can demonstrate that your most critical information receives appropriate protection while avoiding over-classification that wastes resources.
Improved Incident Response
During security incidents, classification speeds up impact assessment. If a “public” folder gets compromised, you can focus on containment rather than panic. If “restricted” data is involved, you know immediate escalation is required.
Essential Information Classification Tools
Data classification tools have evolved from simple tagging systems to sophisticated AI-powered platforms that can automatically identify and classify information based on content, context, and compliance requirements.
Top-Tier Enterprise Solutions
Microsoft Purview Data Loss Prevention leads the pack for organizations already using Microsoft 365. It automatically classifies emails, documents, and cloud data based on content analysis and user behavior patterns.
Varonis Data Classification excels at discovering hidden sensitive data across file shares and databases. I’ve seen it identify thousands of forgotten files containing Social Security numbers and credit card data that organizations didn’t know existed.
IBM Guardium Data Protection provides real-time classification and monitoring, making it ideal for regulated industries that need continuous compliance validation.
Specialized Classification Solutions
For organizations needing specific features:
- Boldon James Classifier integrates seamlessly with Microsoft Office applications
- Digital Guardian combines classification with advanced threat detection
- AWS Macie offers cloud-native classification for Amazon environments
Implementing Automated Information Classification
Automated information classification solutions reduce human error and ensure consistent application of policies across your entire data ecosystem.
Machine Learning-Powered Discovery
Modern tools use pattern recognition to identify sensitive data types:
- Credit card numbers through format analysis
- Personal information via named entity recognition
- Confidential documents using contextual clues and metadata
Metadata-Based Classification Techniques
Metadata-based classification examines file properties, creation dates, author information, and access patterns to determine appropriate classification levels. This approach works particularly well for structured and unstructured dataclassification challenges.
Overcoming Common Classification Challenges
Employee Adoption and Training
Employee training on classification policies remains the biggest hurdle. Start with clear, simple guidelines and real-world examples. I recommend using “classification champions” in each department who can answer questions and reinforce policies naturally.
Handling Unstructured Data
Classification for unstructured data requires sophisticated content analysis. Email threads, presentations, and multimedia files need intelligent parsing to identify sensitive content automatically.
Regular Review and Updates
Regular review of data classification status prevents policy drift. Set up automated reminders to reassess classification levels quarterly, especially for dynamic business data that changes importance over time.
Measuring Classification Success
Track these key metrics to evaluate your classification program:
- Percentage of data classified: Aim for 95% coverage
- Classification accuracy: Measure through periodic audits
- Time to classify new data: Should decrease with automation
- Security incident impact reduction: Track before/after breach costs
Conclusion
Effective information classification for better security transforms data chaos into organized protection. The law firm from our opening story? They now classify 98% of their data automatically, reduced security spending by 30%, and passed their last compliance audit without a single finding.
Classification isn’t about making data harder to access—it’s about making the right data accessible to the right people while keeping sensitive information locked down tight. Start with clear policies, invest in the right tools, and train your team well.
Ready to organize your data for better security? Begin by auditing your current data landscape and identifying your most critical assets. Share your classification challenges in the comments below—I’d love to help you develop a strategy that works for your unique situation.
Frequently Asked Questions
What is the difference between data classification and data labeling?
Data classification determines the sensitivity level and handling requirements for information, while data labeling is the visual or systematic tagging process that marks data according to its classification. Think of classification as the decision-making process and labeling as the implementation method.
How often should data classification be reviewed or updated?
Data classification policies should undergo comprehensive review annually, with quarterly assessments for high-value or rapidly changing data sets. Automated tools can flag classification changes in real-time, but human oversight ensures policies remain aligned with business objectives and risk appetite.
What are the risks of poor or no information classification?
Organizations without proper classification face increased data breach costs, compliance violations, inefficient security resource allocation, and difficulty responding to incidents. Poor classification can result in over-protecting low-value data while under-protecting critical assets, creating both security gaps and operational inefficiencies.
How does information classification impact access control decisions?
Information classification and access control work together to enforce security policies. Classification levels determine who can access data (role-based permissions), how it can be shared (internal vs external), and what additional security measures are required (encryption, multi-factor authentication).
Can automated classification tools handle all types of data?
While automated information classification solutions excel at identifying structured data and common sensitive patterns, they still require human oversight for complex contextual decisions, proprietary information types, and edge cases that don’t fit standard classification rules.
How does classification help with regulatory compliance?
Classification for compliance audits demonstrates due diligence in data protection. Regulators can see that organizations understand their data landscape, apply appropriate controls to sensitive information, and maintain proper documentation for audit trails and incident response.
Sources: